Beginner’s Guide to Regular Expressions with Examples¶
Regular expressions, or regex, are patterns used to match strings of text. They can be very useful for searching, validating, or manipulating text efficiently. This guide will introduce the basics of regex with easy-to-follow examples.
What is RegEx?¶
A regular expression is a sequence of characters that define a specific search pattern. It is often used in:
- Search operations (e.g., finding phone numbers or email addresses)
- Validation checks (e.g., validating passwords or input fields)
- Replacing text (e.g., formatting text or data cleaning)
Some people think that regular expressions are very complicated but I assure you, by the end of this article you will be able to read, create and analyse them easily!
When you see something like s/\\\\/\/\//g or
^([a-zA-Z0-9_\.-]+)@([\da-zA-Z\.-]+)\.([a-zA-Z\.]{2,63})$ it could terrify
you, but let's look forward and hopefully we will be able to see what this
gibberish means by the end of the article.
Basic Syntax and Examples¶
In most programming languages, as well as in some interpreters, / characters
are used to delimit a regular expression. Thus, /pattern/ represents a
regular expression that matches the pattern between the two / symbols. There
may be letters before or after the / symbols - these are called modifiers or
flags.
Also you can see regular expressions with three / symbols. In this case we
are replacing the first part (that matches the regular expression) with the
second part.
Let’s look at some key elements of regex syntax with examples.
1. Literal Characters¶
- Pattern:
/apple/ - Description: Searches for the exact word "apple" in text.
- Example:
- Text: "I bought an apple."
- Matches: "apple"
This is the easiest example. We are searching for an exact sequence of
characters (apple) within the given string. As we did not provide any case
matching flags in the regex, this will only match apple, not Apple,
APPLE, or any other case combinations.
2. Metacharacters (Special Characters)¶
These characters have a special meaning in regex:
. ^ $ * + ? { } [ ] \ | ( ).
If you need to search for these characters, escape them with a backslash
(\).
Example:
- Pattern:
/\$100/ - Description: Searches for the number 100 starting with a
$(special character is escaped). - Example:
- Text: "The price is $100."
- Matches: "$100"
Common Patterns and Their Usage¶
This section covers frequently used regex patterns, such as anchors (^
and $ for matching the start or end of strings), character classes ([ ]
for matching specific characters), and quantifiers (*, +, ?, {} for
controlling repetition). Also predefined classes like \d (digits) and
\s (white space), as well as grouping with parentheses and using the
OR operator (|) for alternation. These patterns are essential for
building effective and versatile regex expressions.
1. Anchors: Start (^) and End ($) of a String¶
- Pattern:
/^The/ - Description: Matches strings that start with "The".
-
Example:
- Text: "The cat is sleeping."
- Matches: "The" (only if it appears at the start)
-
Pattern:
/end$/ - Description: Matches strings that end with "end".
- Example:
- Text: "This is the end"
- Matches: "end"
2. Character Classes: [ ]¶
- Pattern:
/[aeiou]/ - Description: Matches any vowel in the text.
-
Example:
- Text: "hello"
- Matches: "e", "o"
-
Range Example:
- Pattern:
/[a-z]/ - Description: Matches any lowercase letter.
- Pattern:
/[a-zA-Z]/ - Description: Matches any letter (lowercase and uppercase).
- Pattern:
3. Quantifiers: *, +, ?, {}¶
*Matches 0 or more occurrences.+Matches 1 or more occurrences.?Matches 0 or 1 occurrence (optional).{}Setting length of the matching block.
Examples:
-
Pattern:
/go*/- Description: Matches all occurrence of character "g" followed by character "o" zero or more times.
- Text: "goo, go, g"
- Matches: "goo", "go", "g"
-
Pattern:
/go+/- Description: Matches all occurrence of character "g" followed by character "o" one or more times.
- Text: "goo, go, g"
- Matches: "goo", "go"
-
Pattern:
/colou?r/- Description: Matches both words as character "u" set to match zero or one time.
- Text: "color, colour"
- Matches: "color", "colour"
-
Pattern:
/o{2}/- Description: Matches exactly 2 consequent "o" characters.
- Text: "spooky"
- Matches: "oo"
-
Pattern:
/[oe]{1,2}/- Description: Matches all occurrence of characters "o" and "e" occurring consequently one or two times.
- Text: "spooky forest"
- Matches: "oo", "o", "e"
4. Predefined Character Classes¶
Most programming languages and interpreters also support specific predefined character classes.
\d: Matches any digit (0-9).\w: Matches any word character (letters, digits, or underscores).\s: Matches any white space (spaces, tabs, newlines).
Examples:
- Pattern:
/\d{3}/ - Description: Matches any three consequent digits in the text.
-
Example:
- Text: "My code is 123."
- Matches: "123"
-
Pattern:
/\w+/ - Description: Matches any word character in the text.
- Example:
- Text: "Hello_123"
- Matches: "Hello_123"
5. Groups and Capturing: ( )¶
- Pattern:
/(dog|cat)/ - Description: Matches either "dog" or "cat".
- Example:
- Text: "I have a dog and a cat."
- Matches: "dog", "cat"
6. Using Escape Characters: \\¶
If you want to search for special characters like . or *, you need to
escape them with a backslash (\).
As mentioned before, in regex, some characters have special meanings (like
. or * for "any character" or * for "0 or more repetitions"). When you need
to match these characters literally - as plain text rather than their special
function - you must escape them using a backslash (\). Escaping tells the
regex engine to treat the character as an ordinary text.
- Pattern:
/\./ - Description: Matches single "dot" character.
- Example:
- Text: "My file is named file.txt"
- Matches: "."
Practical Examples of Regex Usage¶
Validating Email Addresses¶
- Pattern:
/^\w+@\w+\.\w{2,}$/ - Description: Matches simple email addresses.
- Example:
- Text: "john.doe@example.com"
- Matches: "john.doe@example.com"
Finding Phone Numbers (UK Example)¶
- Pattern:
/(0|\+4{2})\d{4}\s\d{6}/ - Description: Matches UK phone numbers in the format "0" or "+44" followed by four digits, space and another 6 digits.
- Example:
- Text: "Call me at 01234 567890."
- Matches: "01234 567890"
- Text: "Call me at +441234 567890."
- Matches: "+441234 567890"
Replacing Text with Regex in Bash (Using sed)¶
In Bash, you can use the sed command to search and replace text with
regex.
- Example:
echo "I love cats and dogs." | sed -E 's/cats|dogs/animals/g'
-
Explanation:
echo "I love cats and dogs.": Prints the original text.sed -E: Enables extended regular expressions.s/cats|dogs/animals/g:s: Substitute pattern.cats|dogs: Matches either "cats" or "dogs".animals: Replacement text.g: Global flag to replace all occurrences.
-
Output:
I love animals and animals.
This Bash example replaces all occurrences of "cats" or "dogs" with "animals".
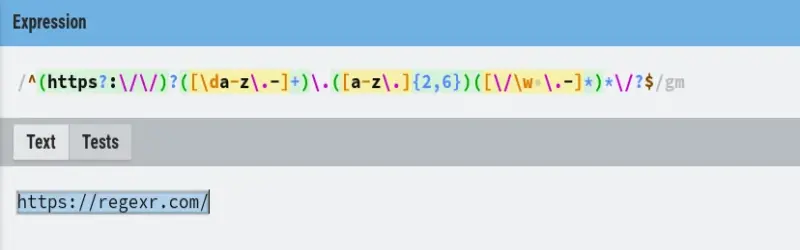
Testing Regex Online¶
You can test and practice your regex skills using free online tools such as:
Conclusion¶
Regular expressions are powerful tools for searching, validating, and manipulating text. While regex can seem complicated at first, practising with small patterns and examples will help you become comfortable using it. Start with basic patterns and gradually experiment with more complex ones to enhance your skills!
And now let's look again on the regular expressions mentioned in the beginning:
s/\\\\/\/\//g and ^([a-z0-9_\.-]{3,15})@([\da-z\.-]{2,15})\.([a-z]{2,6})$.
They may look complicated but let's apply our knowledge and see what they are
doing:
First is just a regular expression for sed to replace the two backslashes
(\\) with two forward slashes (//). It looks complicated as we are
using escape characters to allow us to use the special characters as literal
character.
The second regular expression is a more advanced filter for matching email
addresses. It allows the first part (before the @) to contain dots (.),
hyphens (-), underscores (_), or digits. In the second-level
domain (after the @), it matches the same characters, except underscores. The
top-level domain is limited to 2 to 6 characters.
Quick reference¶
Here is a table explaining the special characters used in regex:
| Character | Description |
|---|---|
. |
Matches any single character except a newline (\n). |
^ |
Anchors the match to the start of a string. Example: ^hello matches "hello" only if it's at the beginning. |
$ |
Anchors the match to the end of a string. Example: world$ matches "world" only if it's at the end. |
* |
Matches 0 or more occurrences of the preceding character or group. Example: go* matches "g", "go", "goo", etc. |
+ |
Matches 1 or more occurrences of the preceding character or group. Example: go+ matches "go", "goo", but not "g". |
? |
Matches 0 or 1 occurrence of the preceding character or group (makes it optional). Example: colou?r matches both "color" and "colour". |
{} |
Specifies an exact number or range of occurrences. Example: a{3} matches "aaa", and a{2,4} matches "aa", "aaa", or "aaaa". |
[ ] |
Character class. Matches any character within the brackets. Example: [aeiou] matches any vowel. |
\ |
Escape character. Used to match special characters literally (e.g., \. to match a period). Also used for predefined classes (e.g., \d for digits). |
⏐ |
Alternation (OR operator). Example: cat⏐dog matches either "cat" or "dog". |
( ) |
Grouping. Groups a part of the pattern. Example: (abc)+ matches "abc", "abcabc", etc. |
Here is a table explaining regex modifiers (flags) used to alter the behaviour of a regex pattern in many programming languages:
| Modifier | Description |
|---|---|
i |
Case-insensitive matching. Example: /hello/i matches "Hello" or "HELLO". |
g |
Global search, matching all occurrences in the string, not just the first one. Example: /cat/g matches every occurrence of "cat" in the string. |
m |
Multi line mode. Changes the behaviour of ^ and $ to match the start or end of each line instead of the entire string. |
s |
Dotall mode. Makes the dot (.) match newlines (\n) as well. Example: /a.b/s matches "a\nb". |
u |
Unicode mode. Enables full support for Unicode characters in the pattern. Example: /\u{1F600}/u matches the 😀 emoji. |
x |
Extended mode (used in some regex engines, e.g., Perl, Python). Allows white space and comments inside the pattern to improve readability. |
These modifiers are typically applied outside the regex delimiters and could be different for some languages. For example:
- Perl, PHP, JavaScript:
/pattern/gim - Python:
re.compile(r'pattern', re.IGNORECASE | re.MULTILINE)
They help fine-tune the search behaviour according to the needs of your application.